Methods and Methodology
Methods
The Intelligence Lifecycle
The intelligence lifecycle is a core method that sits behind Intelligence in general. Some texts explain intelligence as a process, as well as a description for a product. On August the 15th the SIG compared different types of content around the Intelligence lifecycle, as various staged models exist. You can read more about the vote here. The group settled upon a Six Step approach - (Direction, Collection, Processing, Analysis, Dissemination, Feedback (Review): based on the current Wikipedia Reference here
F3EAD Cycle
Moving at the speed of the threat – applying the Find, Fix, Finish, Exploit, Analyse and Disseminate cycle
The F3EAD cycle (Find, Fix, Finish, Exploit, Analyze and Disseminate) is an alternative intelligence cycle commonly used within Western militaries within the context of operations that typically result in lethal action, such as drone strikes and special forces operations. By making small changes to the above narrative i.e. replace “Kill or capture” with “remove or restrict.” Many security teams do the practice of “find-remove-on to the next” and, while that is at the core of the F3EAD cycle, there is still value in defining the process within the confines of the framework.
The intelligence cycle and the F3EAD cycle can be employed closely together to fulfill the overall company’s intelligence requirements, both tactical and strategic. One way of visualizing these two cycles is as cogs turning together within the intelligence process, with intersections between the intelligence cycle’s “Collection” phase and the F3EAD cycle’s “Find” phase. This relationship is shown below.
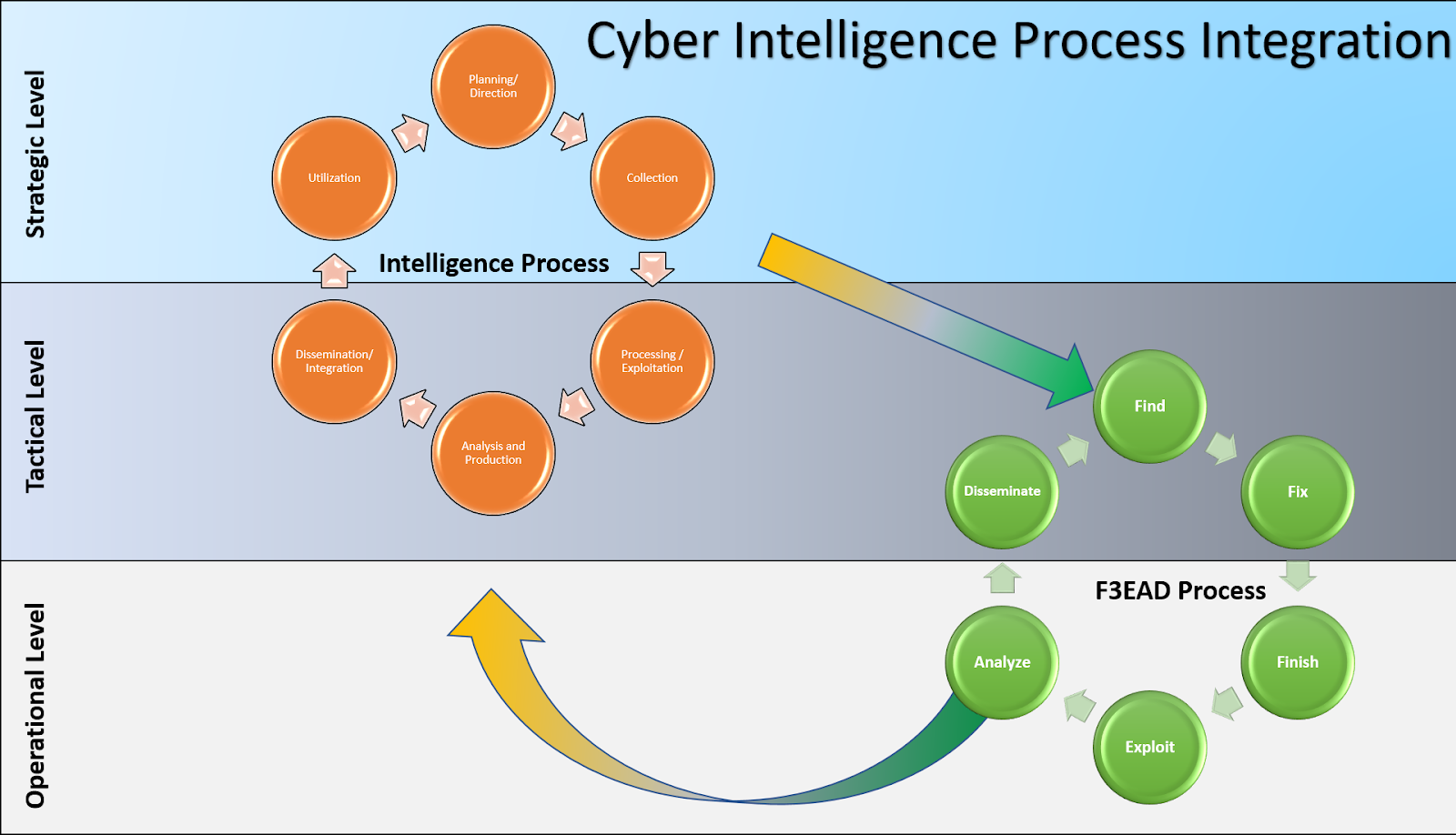
Within this context both cycles can be run in tandem within the context of a single response case.
When Should I use F3EAD?
F3EAD is very good at aligning limited resources in a pressurized situation to answer very specific almost binary questions. For example
- “Have we been breached?”
- “Are we being DDOSed?”
- “Is a threat actor still within our network?”
These types of question often have very simple answers i.e. yes/no however, they are often critical to the overall assessment of the situation. As such within the context of a response case candidates for F3EAD action should be prioritized according to the impact answering the question will have on the overall development of the situation.
When considering this prioritization, the phrase ‘tactical factors that have a strategic effect’ should be in the mind of the operations commander. Returning to the example questions outlined above, all will have indicators at the tactical level however, their impact will have wide ranging strategic implication for the organization.
Based on this F3EAD is a tool that should be used sparingly, with the understanding that focusing on answering one question, de-prioritized other questions. Care needs to be taken to prioritize the correct question based upon the core interest of the business. Taking this principle of prioritization into account and returning to the above example questions, consider the profile of the following organization
Organization 1: Financial institution operating within a highly regulated environment
Suggested priority:
- “Have we been breached?”
- “Is a threat actor still within our network?”
- “Are we being DDOSed?”
Explanation: within this context the immediate concern for the organization will be to communicate with the regulator around the nature of the breach with the follow up question being the nature of the access the threat has to the victim network. The DDOS element is less of a priority at this point due to the core focus on PII of the initial response.
How does it integrate with models like the Kill Chain?
While F3EAD can be used with the model such as the Kill Chain and the MITRE attack frameworks, it should be noted that this is an operational cycle not necessarily a model of the threat such as the former models. As such F3EAD is useful for filling in elements of a wider threat modelling process, IF these element have the strategic impact that was outlined in the previous section.
Having said that F3EAD and the Kill Chain have been more closely integrated – shown below is Wilson Bautista’s example integration of F3EAD and the Kill Chain
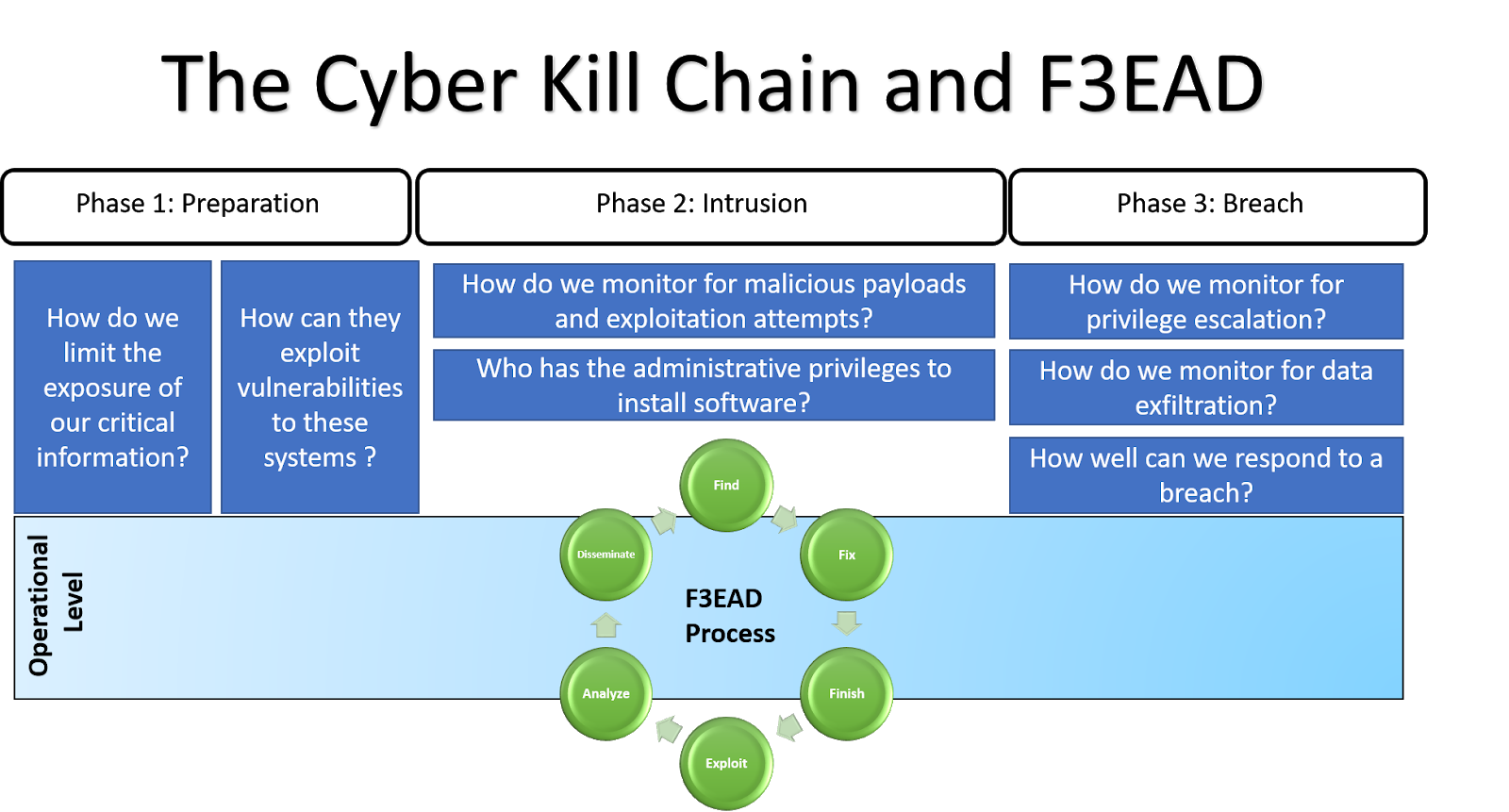
The F3EAD in more detail
| Phase |
Description |
Application Within a Response Context |
Considerations |
| Find |
essentially ‘picking up the scent’ of the opponent, with the classic “Who, What, When, Where, Why” questions being used within this phase to identify a candidate target |
The benefit of these three sections to a response case is that they allow a far more granular appreciation of the resources necessary to achieve the IRs for the tasking.
Find and Fix are essentially getting the team into the position to create the finish effect, be that a site takedown, confirmation of data breach or malware analysis. As these sections are often non-trivial this could put this sub operation out of the scope of the wider operation giving the operational commander a clear go/no go decision in regard to the case |
What Sources and Agencies (SANDA) do I have? |
| Fix |
verification of the target(s) identified within the previous phase, which typically involves multiple triangulation points. This phase effectively transforms the intelligence gained within the “Find” phase into evidence that can be used as basis for action within the next stage |
same as above |
Where possible multiple SANDA should be used to create the triangulation |
| Finish |
based on the evidence generated from the previous two phases the commander of the operation imposed their will on the target |
same as above |
What effect are we trying to achieve with this operation? |
| Exploit |
deconstruction of the evidence generated from the finish phase |
The objective of this phase is not the same as the Analysis phase as the point is to spin off new IRs for another F3EAD cycle that will add to the wider intelligence picture |
F3EAD is meant to be relentless and this phase is the focus point for this drive |
| Analyse |
Really the crux of the matter where the result is analyses and the IR answered |
|
| Dissemination |
finally publishing the results of the research to key stakeholders and fusing the exploited evidence with the wider intelligence picture |
|
Worked Example
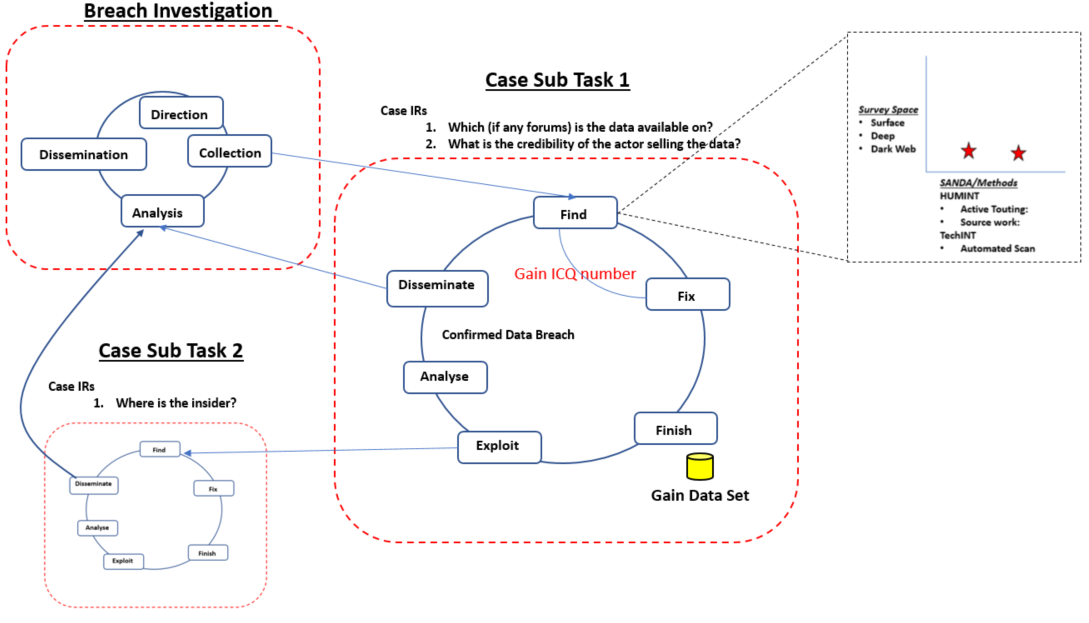
Context: the Organisation has suffered a data breach at the hands of a malicious actor. X number of HR records have been stolen and are now apparently on sale on various Dark Web forums. The Organisation has initiated numerous strands of response one of which is finding if that data is in fact for sale and by who on the Dark Web.
Intelligence Requirements (IRs):
The following IRs are stipulated for this case
- Which (if any forums) is the data available on?
- What is the credibility of the actor selling the data?
Potential Execution:
| Phase |
Activity |
Notes |
Hypothetical Result |
| Find |
Conduct extensive survey of the Dark Web to find instances of vendors selling the breach data.
(This is an example only. Discuss with your lawyers if within your jurisdiction this method of data acquisition is appropriate). |
This ‘search’ is in essence a collection activity however, it is more focused than the more generic intelligence cycle. Search in this case is defined activities which included
- Active Touting: calling out for the data on various forums and chat rooms
- Source work: tasking know sub sources to search for the data
- Automated collection: scraping of multiple forums for keywords on mentions of the data
|
1.The data is being sold on two distinct Dark Web forums, within the VIP area of the site.
- One vendor is selling the data.
Source: automated collection
This also fulfills the first IR of the tasking
- Which (if any forums) is the data available on? – the two forums that where identified earlier
|
| Fix |
Despite knowing where the data is, due to the fact that it was located by an automated bot we do not have direct access to the section of the forum where the actor has posted the advert vending the site. |
In this case there are two options
- Attempt to gain access to the VIP section of either forum
- Approach the vendor via another method to elicit the sale of the data
As time is of the essence option 2 is decided upon resulting in a new Find phase to locate a plausible communication method with the vendor.
|
The vendor is seen to post ICQ Number on a number of other forums. With this we approach the actor and ask directly for the data. We create plausible denial via the ‘someone told me’ method to explain the juxtaposition of our ‘meta knowledge’ about the advert on the VIP section but our lack of ability to gain access to that section of the forum. |
| Finish |
Two possibilities:
- The vendor states the price of 1 bitcoin for the data – we pay and gain a zip file of the data.
- Further possibility: After analysis of the sample data we found that maybe the vendor is not receiving the first source of the data
- we pay and gain the zip of data for further intelligence lead, while re-examining result on “Fix” and maybe back to “Find” steps.
|
This action fulfils the second core IRs of the tasking |
- What is the credibility of the actor selling the data? – highly credible
- How close is the source of data to alleged breach actor? - the vendor is credible but maybe we deal with broker, we may need to trace it further
- Was it the work of insider or adversaries?
How does the breach TTP/IOC say about it? insider / APT / hacktivist / criminals).
- It is the insider’s work.
|
| Exploit |
There are now a number of ways which the situation can be exploited, specifically in regards to the access that has be built with the vendor. The core focus at this point is to understand how the vendor got access to the data in the first instance. |
Using the ‘anymore where that came from?’ tactic we identify that there is an insider feeding the vendor data from the Organisation |
A new set of IRs are generated in order to find the insider |
| Analyse |
The data is analysed |
|
Assessed to be a complete data set |
| Dissemination |
Results passed back to the core response team. |
|
Sub case closed |
Points to note about the above example
Operational speed and cycle stage: F3EAD is meant to be fast and responsive as such sometimes keeping track of which stage of the cycle an operation is active within can be a challenge. As a suggestion the first three stages of the cycle (Find, Fix, Finish) are often the most important in regards to monitoring the most explicit transitions between the stages, note in the example above the Find and Fix stage are somewhat blurred. This is not uncommon but should be remembered in regards to resource management within the context of an F3EAD investigation.
Revising the requirements mid cycle: during the Finish phase there is the option in this case to revise the intelligence requirements of the task. This is reveals two separate ways that F3EAD can be managed, Rigid and Flexible, expanded in more detail below
- Rigid: within this implementation the original intelligence requirements cannot be changed i.e. the team cannot reverse the cycle a stage. As such each individual cycle either succeeds or fails.
- Flexible: within this implementation the original intelligence requirements can be altered mid cycle, also there is the option for the team to reverse the cycle a stage to account for new intelligence that may affect the objective and outcome of the project.
The obvious secondary question in regards to the implementation of a Rigid or Flexible approach to F3EADE, there is no one size fits all answer. A general suggestion however, is that the more F3EAD cycles that are being run the more chance of losing track of the objective of an cycle, especially in a high pressure environment of crisis response. Within this context a more Rigid approach to implementing F3EADE is suggested whereas, a Flexible approach works for operations with a single strand where the objective of a cycle can be easily understood.
Data Processing Techniques
The field of Cyber Threat Intelligence is benefiting from new techniques in computer science, in particular, the sub disciplines of data science and machine learning. These disciplines can help us to automate analysis of cyber threat information at scale, helping practitioners to find features and reveal patterns which support more effective threat classification.
Information collected at scale in the cyber threat intelligence cycle serves as the basis for automated intelligence analysis (processing). Workflows can be applied to data to reduce noise, detect and identify malicious activity, and form a more accurate understanding of adversaries Tactics Techniques and Procedures (TTP). This can be achieved by combining and correlating confirmed indicators of Compromise (IOC) generated from several analysis reports. An important step in the process is to test the data gathered for its confidence and validity.
In the previous sections, we described techniques for Data Consolidation and Data Cleansing, two examples of data science techniques. Once these two steps are complete, the next logical step is to test the data. The following section describes a testing methodology for models that use machine learning.
There is existing work on the machine-technique analysis to help the "Data Testing" process of the prepared data, known as the TIQ-Test (Threat Intelligence Quotient Test).
Threat Intelligence Quotient Test
TIQ-Test ref: https://github.com/mlsecproject/tiq-test.
In the TIQ-test "classic" technique, the prepared data is tested with several methods. Novelty Test will assess how often the data changes (aging test), Overlap Test will check the data in comparison to what we have, and Population Test will check what that data actually contains.
The newer TIQ-test is version 2.0; it introduces new test methods, summarized here: The Coverage Test is a method that allows us to measure how much independent data is provided by each feed we ingest. This information can be used to compare different feeds. The Fitness Test, which is derived from the Population Test of the TIQ-test classic version, evaluates whether a feed has a relationship (correlation) to the environment that is being monitored. And lastly, the Impact Test that assesses how much detection we got out of the prepared data, i.e. we can measure the impact that a certain feed has by calculating the number of true positives a certain feed generated divided by the total number of hits the feed had on our telemetries.
TIQ-test version 2.0 reference: https://www.first.org/resources/papers/conf2018/Pinto-Alex_FIRST_20180624.pdf
TIQ-test (or tool) will withhold judgement and leave the judgement to ourselves. It will compose the input data with an output of the best composition for our data assessment purpose. The tested data will be examined into result so we can decide what further needs to be done for the prepared data.
Below is the breakdown details of the methods used in the TIQ-test:
-
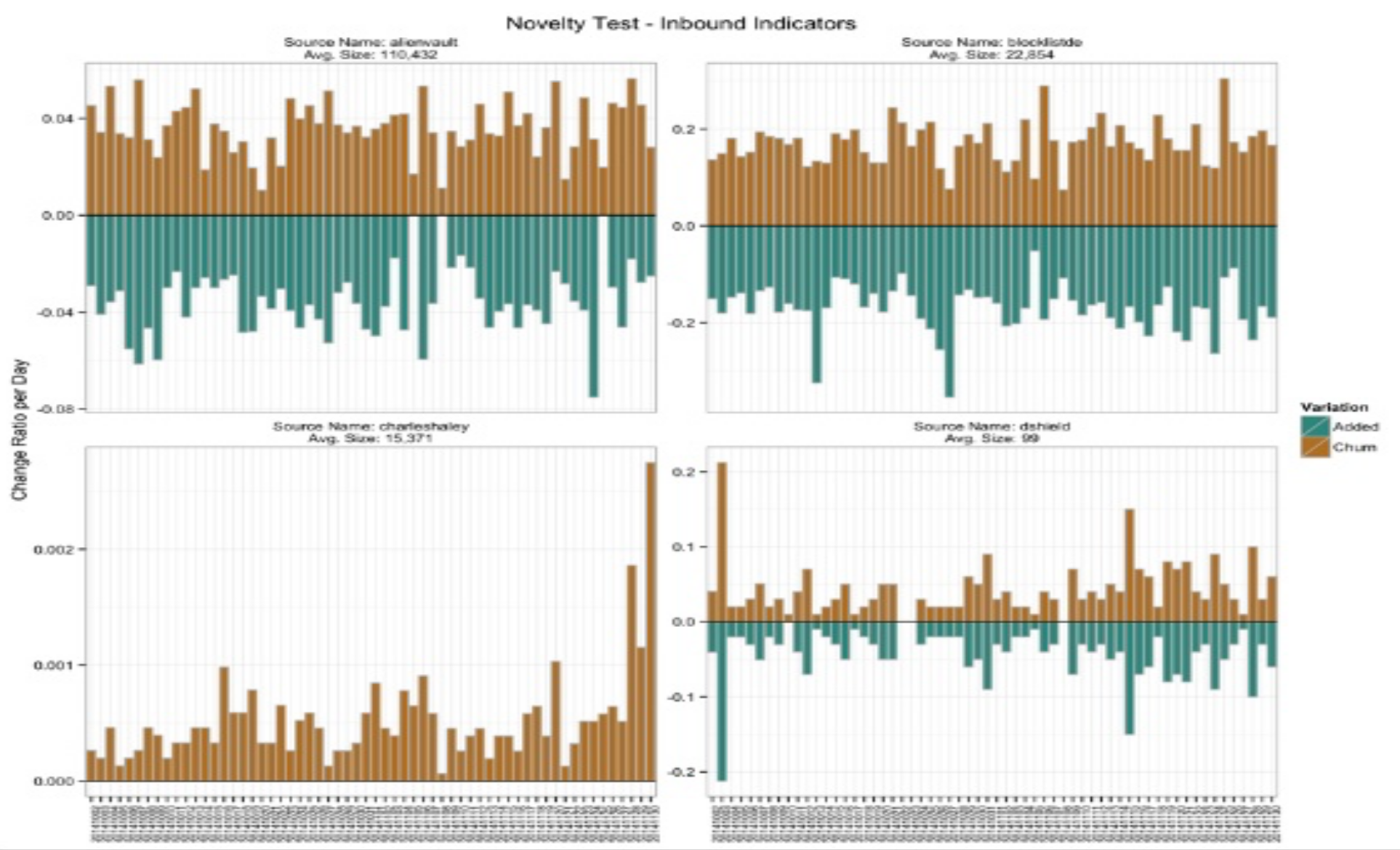
Novelty test: This test explains how often and how feeds change, forming output of the feed progress with time, ratio of addition and churn of atomic indicators in a given timeframe (see below figure).
-
In the Novelty Test there is Aging Test, a sub-test that defines for how long an indicator has been reported in a feed, forming output of average time to live on indicators of TI feeds and how often atomic indicators are removed from the distribution list.
-
Overlap test: This test explains how they compare to what we have - how unique are the ingested feeds, and how many indicators are present on multiple TI feeds within a given time frame.
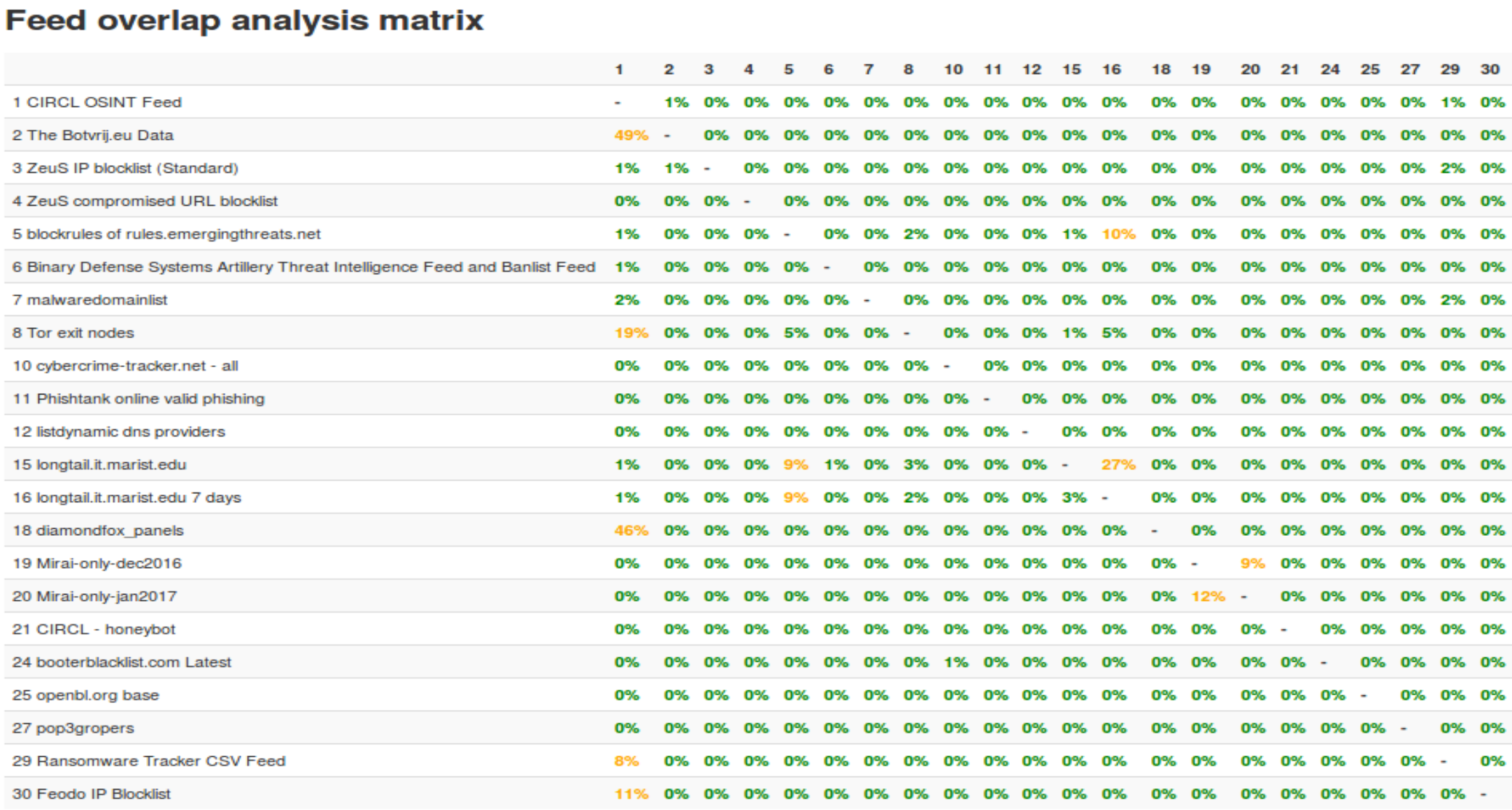
The figure above is a sample explaining the Overlap Test result on several active TI feeds.
-
Population test: This test explains how a TI data set distribution compares to another. Population test is forming a statistical inference-based comparison between the expected frequencies (GeoIP feed’s indicator distribution) and the observed frequencies (of Geo-location data in the monitored environment).
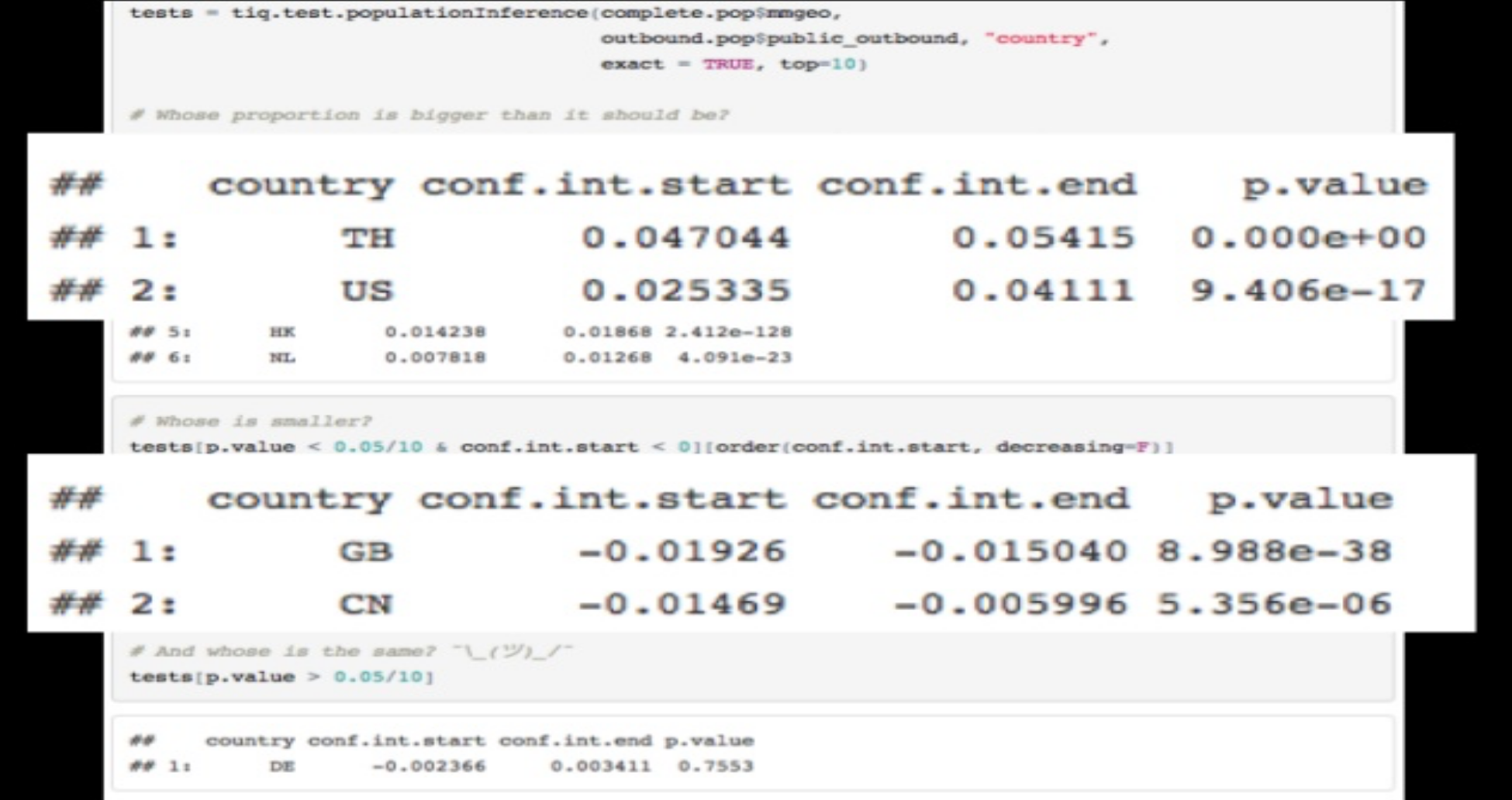
One subtest in Population Test is Uniqueness Test, which can be described as testing the uniqueness result from the prepared data.
In order to improve the previous work, the following tests were added:
-
Coverage Test (or Overlap Test 2.0): As explained previously, Coverage Test is a test to assure us that we get what we need from the TI feeds we consume. This test came up from the Overlap Test that comes out with complicated output.
The coverage test measures how much independent data is being ingested from each feed.
It is good to get unique data from our resources, and for this purpose it is preferable to focus on the “uniqueness” of a certain source, without compromising correctness. We need to be aware of the risk of false positives that can occur as an implication of too much uniqueness spotted in our tested TI feeds. Too unique might also be read as very imprecise, and also the fact that overlap is not necessarily a bad thing. For instance, the fact that an IoC has been reported by two or more different feeds might also contribute (in the case of a hit in our telemetries) to assigning a higher confidence level to the observable/indicator.
-
In other words, we should not confuse coincidence and causality. An overlap may mean either that two sources independently discovered a data point, which in this case is a confirmation, or it may also mean that one feed is based on the other and, thus, is a duplication of an observable (IoC) and is redundant.
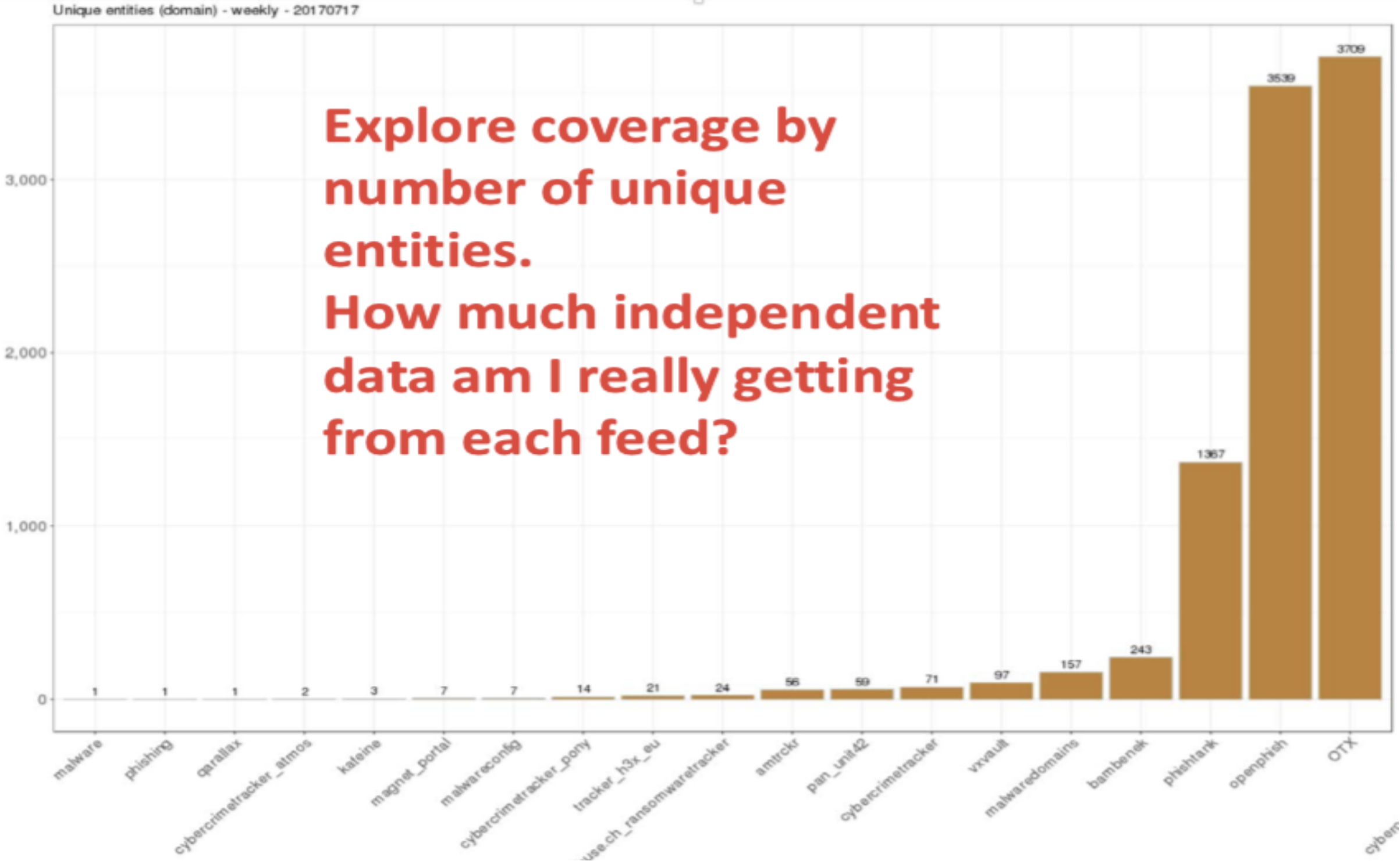
A figure to explain a sample of unique domains that actually meets a user's needs from a certain TI feeds .
-
Fitness Test: This test was developed because the Population Test was not providing enough insight on how much a feed fits in the environment you are monitoring. Trends and population comparisons are good ways to drive detection engines but are a bad way to clearly evaluate whether a feed has a relationship to your environment.
Fitness Test is assessing the detection ratio of our TI resources, as those feeds only matter if they “fit” our telemetry.
The figure below is an example of Fitness Test on UniqueFit analysis output.
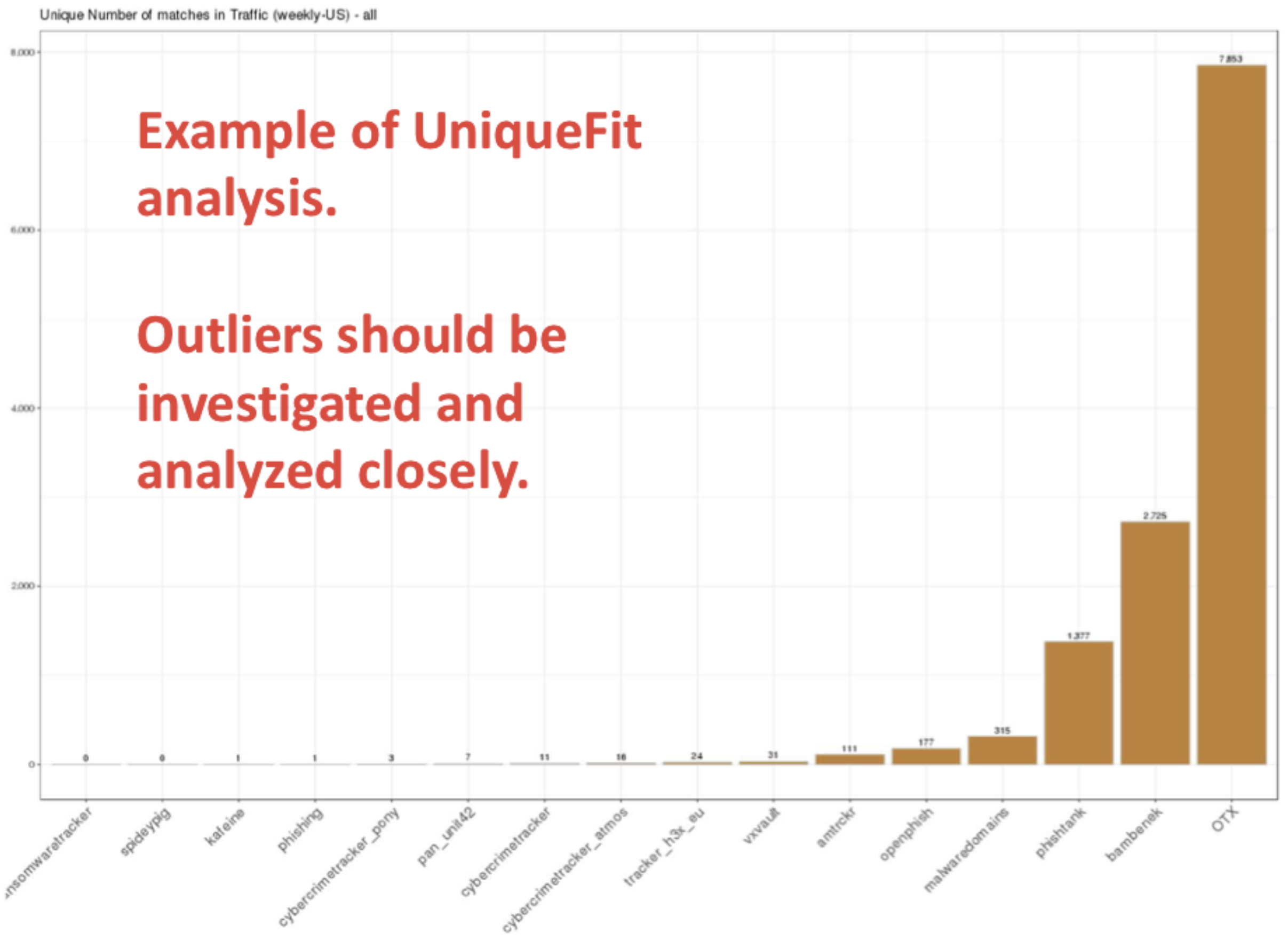
During the Fitness Test, if the output looks bad, that doesn't mean the TI feeds is bad; the indicators provided in those feeds may just don't fit to your telemetry. It is a good opportunity to evaluate the feeds or telemetry itself;making an evaluation to adjust your feeds or telemetry may sharpen the result.
If the Fitness value is too high, it could also mean the TI feeds contain a high number of false positives, unless the feeds themselves are too different. We may need to assess what is causing the false positive to sharpen the result.
-
Impact Test: This test shows the actual efficiency of the TI feeds collected in making good or bad detection. Good alert is an alert that was “correct” even if it had not been triggered by an IoC, but we have learned from it. For example, by leveraging the metadata (enrichment) of IoCs to derive a higher order of detection from it.
If someone asks us, "How much detection we can get from our TI resources?", then the Impact Test is the best way to summarize the scoring for it.
Below is the example graph on Impact Test on alert feed efficiency.
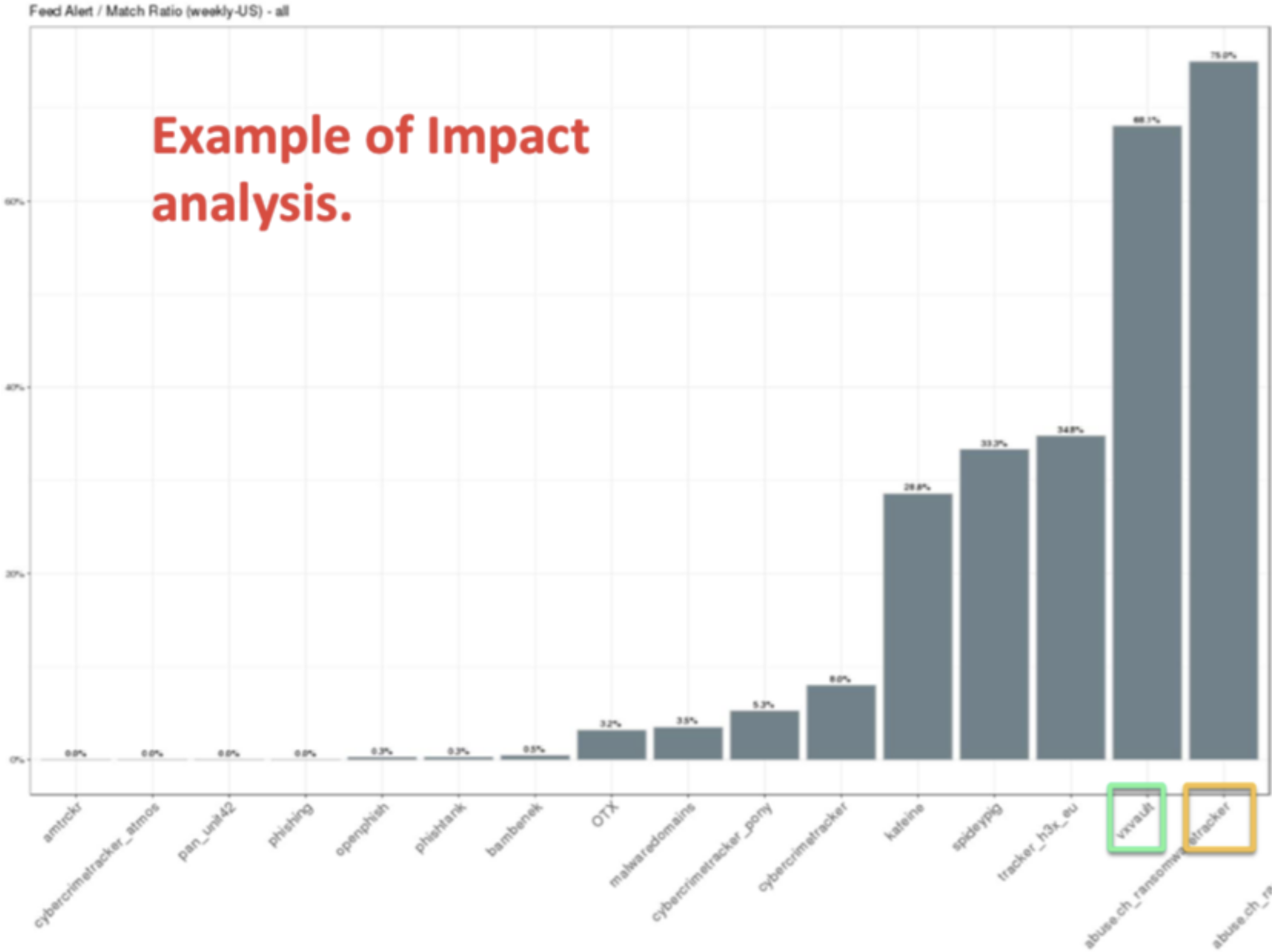
The raw/primary observables (IoC) are first-hand data points directly gained from cyber threats and incidents and are not derived from other indicators or come out of data processing. While we process those primary indicators and make conclusions, derive indicators (including TTPs) from them, thus it may appear we are “climbing the pyramid”. In this sense, the usage of the Impact Test is not useful to predict the future threat but allows us to build the TTP knowledge about a specific threat that we follow.
External sources
